Author: Yellow
关于
本文是以一种简单易懂的方式阐述Java NIO中一些基本但是可能让初学者费解的概念,参考了《进击的Java新人》和互联网上的一些资料,内容不仅限于Java,可能会牵涉到一些计算机的基础知识,比如I/O模型、操作系统知识等。
前言
当前这个时代,随着上网成本越来越低廉、终端性能越来越强大、应用种类也越来越丰富,互联网已触及我们生活中的每个角落。如今,如果一个年轻人从没点过一次美团外卖,或者从没玩过网络游戏或看过网络直播,那么他可能会被认为是刚从山洞里走出来的原始人。
而这一切便利的互联网服务的背后,是由一系列复杂的技术做支撑的,如何保证在海量用户访问的情况下服务还能稳定并且快速,这成了很多企业要着手解决的问题,毕竟谁都不想自己的产品三天两头崩溃打开一个页面要十几秒吧,如果真要那样,估计boss会提着菜刀在办公室等你了(参考J东)。
然而不管一个公司的业务是游戏,还是外卖,亦或是社交,其本质都是网络应用(包括客户端与服务器的交互、服务器与服务器的交互),所以一个公司如何想handle大量的数据、大量的用户与大量的交互,高性能网络编程必须得玩的溜。
对于大部分SSHJava程序员来说,拿SSH开发Web应用应该是家常便饭了,但如果把SSH拿掉,让他做一个网络应用(比如一个IM),他可能就懵逼了。个人认为,“框架”的确是一个好东西,特别是对于做项目、提高生产率来说;但是另一方面,如果一个程序员只是想着怎么去使用这些框架,而忽视了很多更核心更基本的东西,那对于他的个人发展来说,无异于故步自封。(见Java程序员的堕落)
另一方面,对于SSH中的核心Spring来说,其性能在不同语言的各种Web框架中也是几乎垫底的(见这个Benchmark),但是同样是基于Java的Netty却名列前茅,所以Java本身性能并不弱,弱的是Spring使用的堵塞式的I/O模型(但是最新的Spring 5似乎推出了能支持非堵塞I/O的Spring WebFlux,这个有带考察)。
所以,为了了解或者入门高性能网络编程,I/O模型的学习一定是重中之重,下面就会来谈一谈这方面的东西。(个人觉得,I/O这个东西一直都是拖累系统性能的吊车尾:内存拖累CPU、硬盘拖累内存、……,于是牛人们为了让系统不至于被拖累得那么惨,捣鼓出了各种玩意,比如Cache、LazyLoad等… 扯远了)
JavaNIO之一:传统I/O与NIO的关系
诞生历史
从Java诞生开始,伴随着JDK1.0,Java程序员们就有了相应的I/O类可以使用,比如大家熟悉的老朋友InputStream、OutputStream等等,基本都集中于java.io这个package下面。那时候用户量小,数据量小,所以大家都用得很开心。那时候的代码大概长成这个样子:1
2InputStream is = new FileInputStream(“a.txt”);
byte b = is.read();
到了大概两千年初,Java在其JDK1.4版本中包含了一个新的朋友:java.nio,提供了对非阻塞I/O的抽象(对下需要依赖OS的实现)。有人认为nio = Non-Blocking I/O,但是官方宣传nio = New I/O,然而是哪个并不重要,只要跟老朋友阻塞式Blocking I/O(BIO)区分开就行。
之后到了JDK1.7的时候,Java又引入了一个更新的朋友:AIO(具体的Class也是在nio package下),负责对异步I/O(Asynchronous I/O)进行抽象,然而很多OS的AIO的实现并不给力,效率不高,所以实际用处并不大。我们下面的内容主要是基于Non-Blocking I/O。
我们看到Java为我们带来了很多新朋友(Class、package),但是有一点要注意的是Java并没有创造任何I/O模型,I/O模型必须OS层面提供支持,并以syscall的形式暴露出来,Java做的工作实际上是对这些syscall的再一次封装。
有什么用处?
现代高性能服务器(Game Server、Web Server、IM Server…)、高性能通讯框架的基础,比如Netty、Nginx、Node.js、Redis、Dubbo等,虽然它们的编程语言并不相同,但是都是依赖于OS底层提供的能力实现的,最终的编程模型并不相差太多。业界经常说的C100K之类的问题,靠BIO基本是解决不了的,通常都是需要 Non-Blocking I/O(具体原因会在下面章节阐述)。所以理解这些新的I/O模型,是学习与从事高性能网络开发工作的前提。
JavaNIO之二:三大组件(Buffer、Channel、Selector)
JavaNIO基本上是围绕这3个东西进行编程:
- Buffer:缓冲区,也就是内存中一块用来暂存数据的固定大小的区域。可以想象成一个用于装水的玻璃缸;
- Channel:通道,数据可以通过Channel写入Buffer或从Buffer读取到别的地方,主要分为文件Channel和网络Channel两大类。可以想象下我可以用一根水管一端接水龙头,另一端伸到玻璃缸里,那么水就能源源不断地流入玻璃缸了,这根水管是一个往Buffer写数据的Channel;我还可以用另一根水管把水从玻璃缸中抽出到其它地方,这根水管是一个从Buffer读数据的Channel。
- Selector:I/O多路复用的选择器,与Channel配合使用,是实现Non-Blocking I/O、高并发的关键,只能用于网络Channel,所以暂时先放一边,等到网络Channel时会一起讲。
所以对于前两者,它们的关系大概如下图,但是注意写入或读取的Channel都可以有多个,不仅限于一个。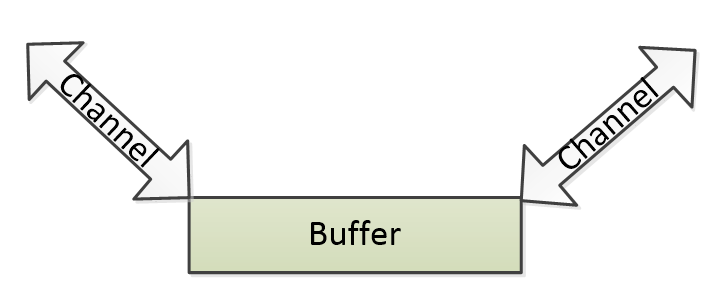
JavaNIO之三:三大组件之Buffer
总体概述
学过计算机的同学应该不难理解什么是(一般意义上的)Buffer,其实JavaNIO中的Buffer类也是类似:一块尺寸在初始化之后就固定的内存区域,用来暂时存放数据。下面给出Buffer家族的类层次图: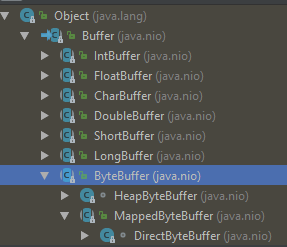
可以看到其实Buffer是一个抽象类,在其之下是对应所有包装类型的抽象Buffer类,其实就是属性中增加了一个对应的原始数据类型的数组(比如DoubleBuffer里面比Buffer多了一个double[])。再往下就是具体的实现类,基本上每种数据类型都至少对应两种:HeapXXXBuffer(在Java Heap中分配)和DirectXXXBuffer(在本地内存中分配),比如ByteBuffer下面的HeapByteBuffer和DirectByteBuffer。
Buffer的重要属性和操作
首先要说明的是,NIO中一些类的设计思路跟老的BIO类有些不一样,BIO虽然也可以自己new一个byte[]作为InputStream读取数据时的目的地,或OutputStream写数据时的目的地,但往往我们只需要把这个数组传进去read()或write()就行了,不需要知道读到或写到数组的什么地方,之后的工作Stream会帮我们做了。
然而NIO的使用方式相比起来却有点“原始”:管理Buffer读到哪、写到哪的工作不由Channel负责,而是回到Buffer自己身上,由程序员自己控制。最重要的属性(下标)有3个:
- position:指向当前可被操作的位置(操作为读or写)
- limit:指向可被操作的边界(如果是写操作,则表示空闲位置的边界;如果是读操作,则表示有效数据的边界)
- capacity:Buffer的Size,Buffer被初始化之后就是一个固定值
它们的大小关系是:position <= limit <= capacity。只看文字有点抽象难理解,下面会结合图示说明。为了方便理解,你可以认为Buffer具有两种模式:读数据时处于读模式,写数据是处于写模式。然而实际上Buffer并没有这两种模式的设置,只是你可以逻辑上这样认为。
1.初始化
一个刚刚初始化好的空的Buffer(可以理解成做好准备可以写数据了!)长这样: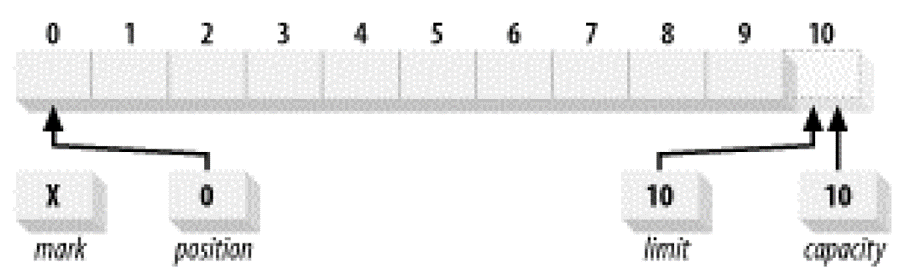
mark是什么可以先不管。capacity就是初始化时设定的Buffer的Size,这里是10。position指向的是当前可以被操作的位置,因为我们现在是写模式,所以它指向的是当前可以写的一个空位。limit则指向可写的边界,可以理解成写到哪就不允许继续往下写了,因为我们这是刚刚创建的空Buffer,默认下可以写到全部满位置,所以这时候limit = capacity = 10。
2.顺序写入几个字符
假设我们现在依次往Buffer里面写入5个字符 H、 e、 l、 l 、o:1
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
则每写入一个字符,position都会向右移一个位置,写了5个字符后,它就指向5这个位置。现在它看起来像这样: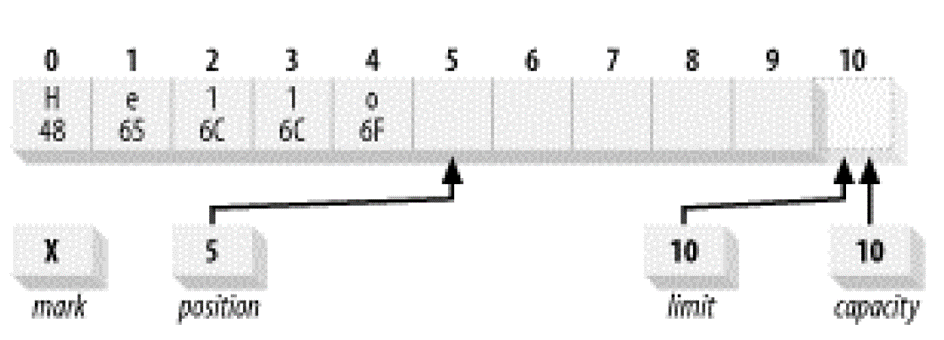
3.随机写入
假设我们要直接修改Buffer中的某个位置,可以这样做:1
buffer.put(0, (byte)'M');
这样做会把原先位置0的字符‘H’修改为‘M’,并且随机写入不会改变position的位置(它还是指向5)。如果这时候我们再顺序写入一个字符‘w’,这个字符是会写在位置5的,现在它看起来像这样:1
buffer.put((byte)'w');
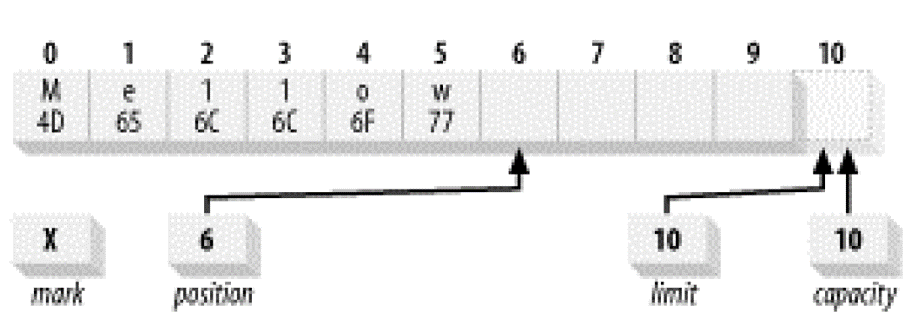
4.翻转!变成读模式
PS:flip操作经常会让刚接触NIO的人费解!所以下面内容请仔细阅读!
假设现在我们要读出Buffer里的数据,直接调用get()是不行的,因为读操作也要依赖position、limit,而这时候position是指向一个空位置,所以读不出先前写进Buffer里的数据。于是这时候我们需要一个翻转操作:1
buffer.flip();
flip()执行后产生如下效果:
- 当前limit变成先前position的值;
- 当前position变成0。
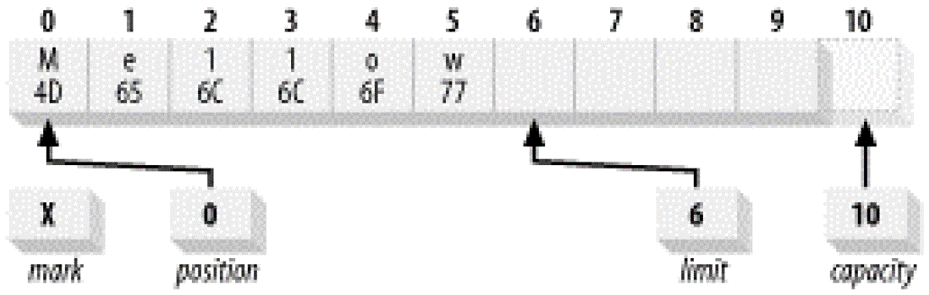
可以简单理解成Buffer变成了读模式,position指向了当前可以被读的字符,limit则指向字符串的尾巴(也就是最多允许读到哪里为止)。之后就可以调用get()来读取数据了,每次读position都会往右移动一个位置,直到limit为止。
总结
上面罗列了Buffer的3个重要属性和flip操作,其中理解flip操作非常关键。可以想想,如果我们连续调用两次flip(),会产生什么效果?答案就是这个Buffer变成既不能读也不能写了,因为position、limit都指向0了。
Heap Buffer与Direct Buffer
一般我们new出来的Buffer都是在Java Heap中分配的空间,在里面的空间可以被GC回收,但有时候我们为了性能考虑,比如不想GC干扰或增加GC压力,可以考虑在Java进程中的Native内存中分配Buffer,这时候的Buffer称为Direct Buffer,可以通过allocateDirect(int capacity)获得。但是分配在Native内存中的Buffer不能被GC回收,所以如果要使用,请参考这里:Deallocating Direct Buffer Native Memory in Java for JOGL
Heap Buffer与Direct Buffer在Java进程中的布局图如下所示: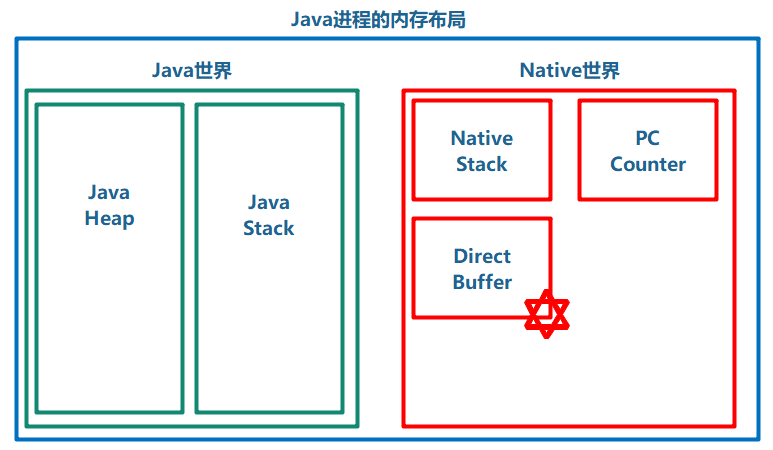
JavaNIO之四:三大组件之Channel
Channel可以想象成一个管子,一头连接着I/O数据来源/目的地(文件、网络等),一头连接着Buffer,数据可以在这两者之间传输。
Channel按照面向的设备的不同,可以分为两种:
- FileChannel(面向磁盘文件)
- SocketChannel、ServerSocketChannel(面向网络数据流)
SocketChannel、ServerSocketChannel将在之后跟着Selector一起讲,这里先讲FileChannel。另外从JDK1.7开始多了一些以Asynchronous打头从Channel类,这是属于AIO部分的东西,这里也不作阐述。
如何使用
可以通过FileChannel类的open()函数方便地创建一个与某个文件关联的FileChannel对象。常用的API大概有下面这些:1
2
3
4
5
6
7public abstract int read (ByteBuffer dst, long position)
public abstract int write (ByteBuffer src, long position)
public abstract long size()
public abstract long position()
public abstract void position (long newPosition)
public abstract void truncate (long size)
public abstract void force (boolean metaData)
用起来跟Stream类差不多,特别注意的是force()这个函数,它可以强制OS把数据刷写到磁盘上,因为有时候我们对FileChannel进行写入时,数据不一定已经落到磁盘上,可能在OS的cache中。
内存映射文件(Memory Mapped File)
如果不提及内存映射文件,那么NIO中的FileChannel用起来其实跟BIO的Stream差不多。然而这个特性是NIO开始引入的(底层还是依赖OS的支持),能在一些场景下提供非常好的性能,所以应该重点关注。
虚存空间(Virtual Address Space)
要讲清楚什么是内存映射文件,必须先弄明白什么是虚存空间(以下简称VAS)。VAS可以理解成进程运行的“沙箱”,每一个进程都运行在一个单独的VAS里,在32bit的机器上,这个VAS大小为4GB。那是不是表示如果运行了10个进程,就需要占用10 x 4GB = 40GB的内存呢?显然不是的,其实VAS只是一个虚拟概念,只是从进程角度看,它觉得自己拥有一个4GB这么大的内存空间,它可以load一段数据并放在地址0x12345678这个位置,然而在真正的物理内存这边,数据并不一定是放在这个地址,虚存地址和物理内存地址之间需要靠一个叫内存管理单元(MMU)的硬件做转换。可以参考下面图示,如果还是不懂,可以自行Google。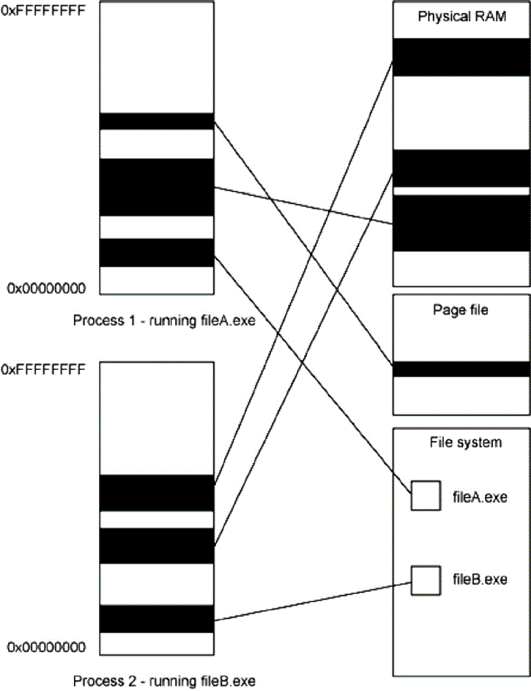
这样做好处主要是可以隔离不同的进程,防止恶意进程对其它进程进行破坏。
另外一方面,4GB的虚拟空间进一步可以分成2部分:内核空间和用户空间。CPU也有两种运行状态:内核态和用户态。内核空间里一般放驱动、硬件缓冲区等敏感信息,不能随意读写,而用户空间则存放一般经常分配的内存空间。CPU在用户态时,可以访问用户空间,但不能访问内核空间和执行里面的代码;CPU变成内核态后,可以访问内核空间和读写硬件。用户态到内核态之间的转换一般通过中断或系统调用(system call)。
BIO vs. Memory Mapped File
现在可以来解释内存映射文件了。首先我们来看老的BIO读文件时,数据是怎样在设备和内存中跑的: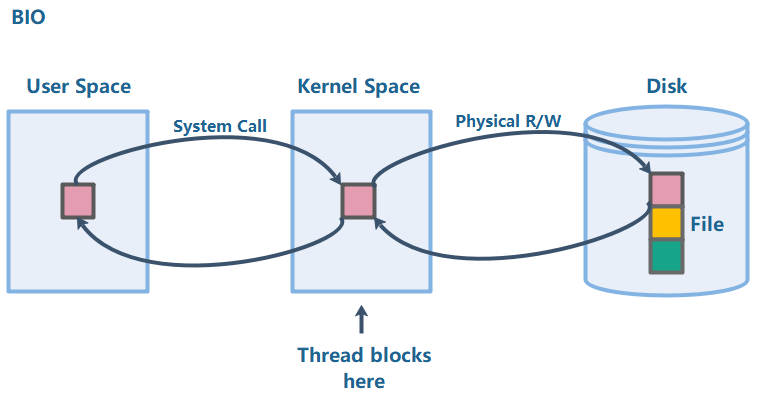
假设一个文件在Disk中,大小是3个块,现在进程想读取文件的第一个块。
- 首先,进程发起一个系统调用,这时候CPU变成内核态;
- CPU在内核空间开辟一块缓冲区,并命令Disk把数据装载到这个内核缓冲区中,这时候进程需要堵塞等待硬件完成这个数据装载;
- 数据装载到内核缓冲区结束,进程把数据从内核缓冲区Copy到用户空间。
从这个步骤可以看出,数据经历了2次Copy:Disk -> 内核空间,内核空间 -> 用户空间。写数据到Disk的时候流程也是类似,可以看出在数据量大的情况下,这种方式比较低效。
在支持内存映射文件的OS上,可以绕过内核空间,直接把整个文件“投影”到用户空间,这个“投影”操作时很快的,然而这时候它并不真正的Copy数据到用户空间,只是对于进程来说“看起来像是”整个文件都在内存中了。当进程需要文件的第一块数据时,会产生一个Page Fault,OS会自动从Disk帮忙把第一块数据加载到用户空间中;类似的,写数据只需要写入用户空间,而不需要堵塞,OS会帮忙同步回Disk中。图示: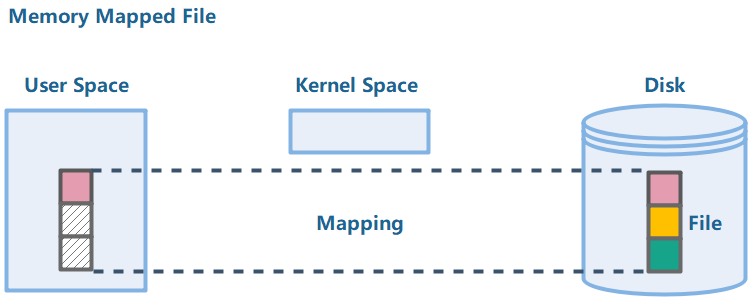
这项特性主要应用场景有:高性能文件随机读写、高性能进程间通信(不同编程语言也可以)
Java API
FileChannel类中有一个map()函数:1
public abstract MappedByteBuffer map(MapMode mode, long position, long size)
MappedByteBuffer是一个抽象类,从JDK1.8代码上看只有一个实现类DirectByteBuffer,它是上面我们讲过的在Native空间分配的Direct Buffer。例子代码可以在自行Google。
JavaNIO之五:三大组件之Selector
由于Selector只跟网络的Channel有关,所以它们放到这里一起讲。
堵塞式I/O的年代
回忆下以前学Java Socket编程时一个最简单的服务器-客户端例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Server {
public static void main(String args[]) throws IOException{
ServerSocket ss = new ServerSocket(8080);
Socket conn = ss.accept(); // 堵塞!
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(conn.getOutputStream()));
String s = br.readLine(); // 堵塞!
while (s != null) {
System.out.println(s);
bw.write(s.toUpperCase() + "\n"); // 堵塞!
bw.flush();
s = br.readLine(); // 堵塞!
}
br.close();
bw.close();
conn.close();
}
}
1 | public class Client { |
这是个很简单的例子,先运行服务器,进程会堵塞在ss.accept();这个地方,然后再运行客户端,它们会建立链接。之后客户端会发送“hello”和“world”两个字符串给服务器,服务器收到后打印出来,之后就退出。实际上上述代码注释里标注了“堵塞!”的地方都会产生堵塞,因为都牵涉到网络I/O,线程必须等待数据准备好了(已经从网卡读入到内核缓冲区了,或者已经从用户空间写入内核缓冲区了,参考上面章节的文件I/O),才能继续运行。
从这个例子可以看出一个问题:当服务器线程正在为一个客户端服务时,是不能服务其它客户端的,如果要同时服务多个客户端,就需要启动多个服务器线程/进程,这就是老的一些http服务器使用的模型。然而这会带来一些问题:
- CPU个数是非常有限的,启动的线程很多的话,势必会频繁地切换,产生非常严重的上下午切换开销;
- 每个线程为了维护一些栈之类的只跟自身相关的信息,也需要占用一定的内存,那么线程一多势必占用大量内存。
加上互联网应用大部分都是一些“慢连接”式的请求,往往大部分时间都在等待数据,只有很少部分时间会传输一点数据(比如在线聊天、网页消息推送…),用堵塞式I/O来处理这些请求,往往到“千”级别的并发就遇到瓶颈了。
不同的网络I/O模型
由于传统的模型行不通了,就需要寻求新的出路。著名的《APUE》里总结了几种网络I/O模型,这里结合一个生活中的例子:学生做试卷。一堆学生在教室里做试卷,假设不规定交卷试卷,学生做完就可以交卷,老师必须拿到试卷回到办公室才能批改。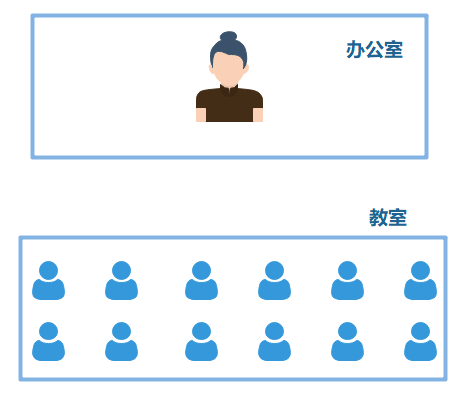
1. 同步 + 堵塞式I/O模型
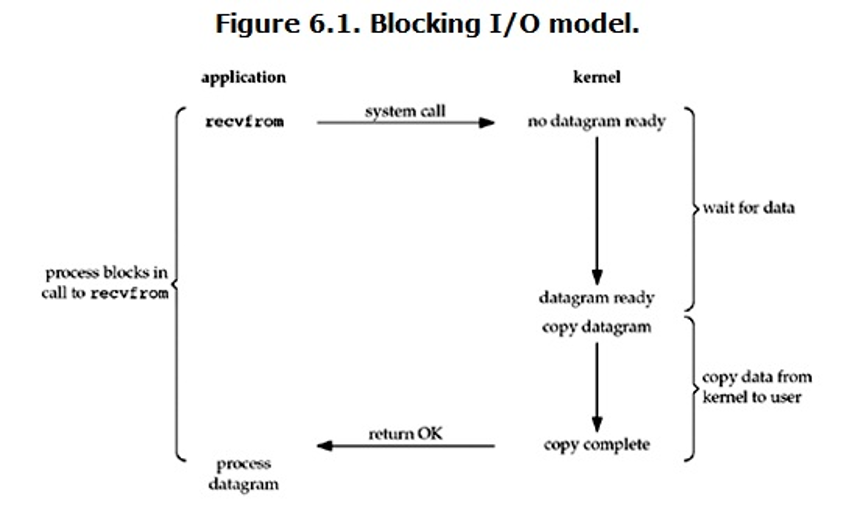
所谓同步,即表示把数据从内核空间Copy到用户空间的过程必须线程自己负责;所谓堵塞,表示发起系统调用之后进程要block住一直等到数据准备就绪。用学生做试卷的例子来说就是,如果只有1位老师,那么这位老师就要站在某个学生旁边一直盯着他做试卷,直到他做完后,亲手把试卷拿回办公室,期间其余同学如果有做完想交卷都是不行的,因为老师只能盯着一开始那位学生。如果想做到每个学生都能自由交卷,就必须每个学生配备一个老师,这堆老师都站在教室里各盯着一个学生做试卷……傻不傻?
2. 同步 + 非堵塞式I/O模型
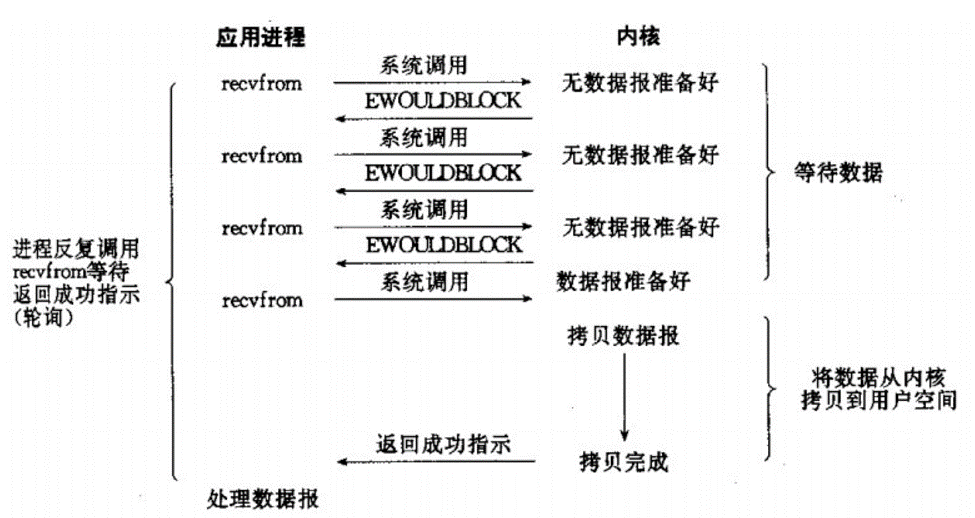
相比之前的模型,现在发起系统调用之后不用block住了,而是可以马上返回,去做其它事情,之后周期性地检查数据是不是准备好,准备好了就拷贝数据到用户空间。这种模型往往跟“I/O多路复用”结合,即一个线程可以monitor多个网络socket。用学生做试卷的例子来说就是,老师把试卷派下去之后,就回办公室玩手机了,而办公室有一个装置,当有任何学生做完试卷了,就会让这个装置发生变化(比如亮灯),老师打完一盘王者荣耀了,抬起头看看装置亮灯了,就走过去教室把做好的试卷收过来。这样一个老师就可以服务多个学生了。
3. 纯异步式I/O模型
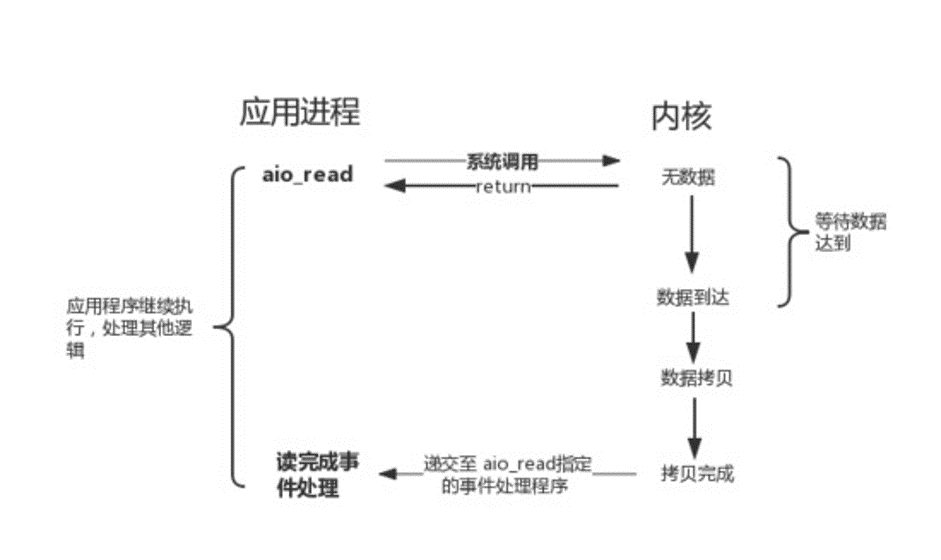
相比之前的模型,这个模型连从内核空间拷贝数据到用户空间都不需要线程自己做了,线程发起请求后留下一个回调接口就可以了,等数据准备好之后就会调用该回调接口。用学生做试卷的例子来说就是,老师派完试卷后就回办公室了,学生做完试卷后自己把试卷拿到办公室给老师。是不是很完美?然而真正OS实现上现在AIO还不成熟,效率甚至还不如NIO。
I/O多路复用(Multiplexing)
I/O多路复用一般是指结合 同步 + 非堵塞式I/O模型,用一个线程监视大量socket的技术,当有socket变成Ready了,这个线程就能获知。一般Linux底层提供的有poll/select、epoll几种技术,poll/select差不多,都是线程只能获知有socket ready了,但是不知道是哪些socket,所以必须要一个个socket去check;而epoll则连哪些socket变成ready了也能获知,所以性能更高。
Selector API
JavaNIO中与I/O多路复用有关的3大类:
- SelectableChannel(Socket & ServerSocket),代表socket
- Selector,监听器,可以监听多个socket
- SelectionKey,抽象表示一个Selector与一个channel的监听关系
SelectableChannel与Selector是多对多关系: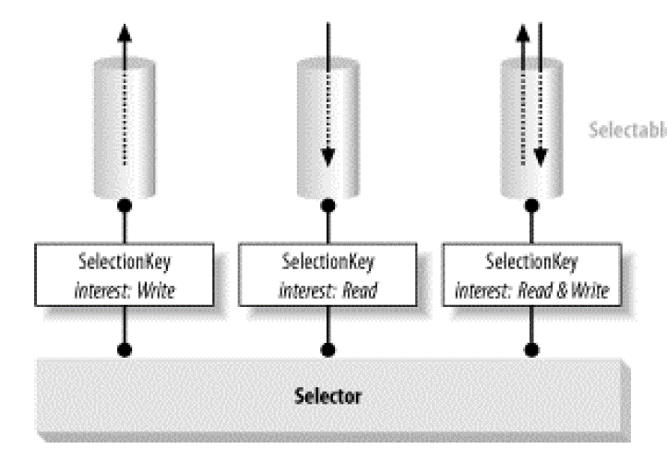
用法参考下面API或自行Google:1
2
3
4
5
6
7
8
9//SelectableChannel(Socket类)
public abstract SelectionKey register (Selector sel, int ops)
//Selector
public abstract int select (long timeout)
//SelectionKey
public final boolean isReadable()
public final boolean isWritable()
public final boolean isConnectable()
public final boolean isAcceptable()