Author: Harry He
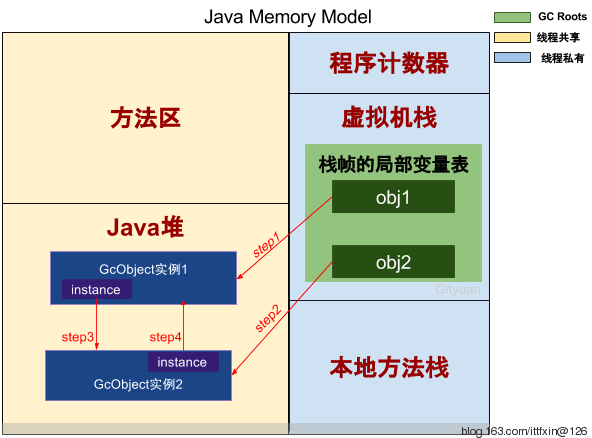
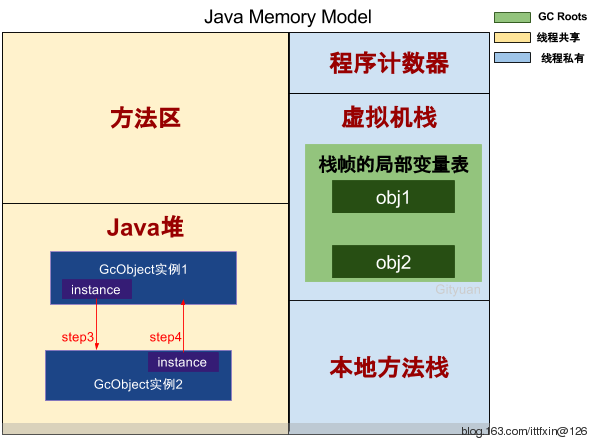
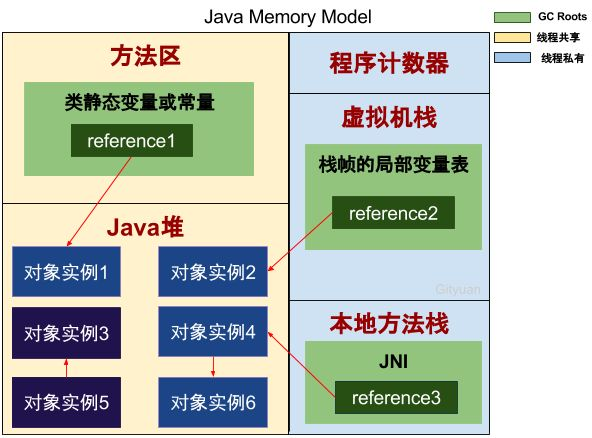
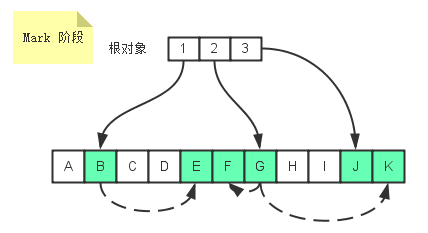
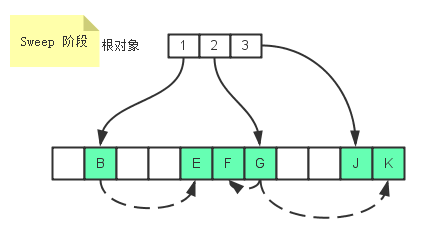
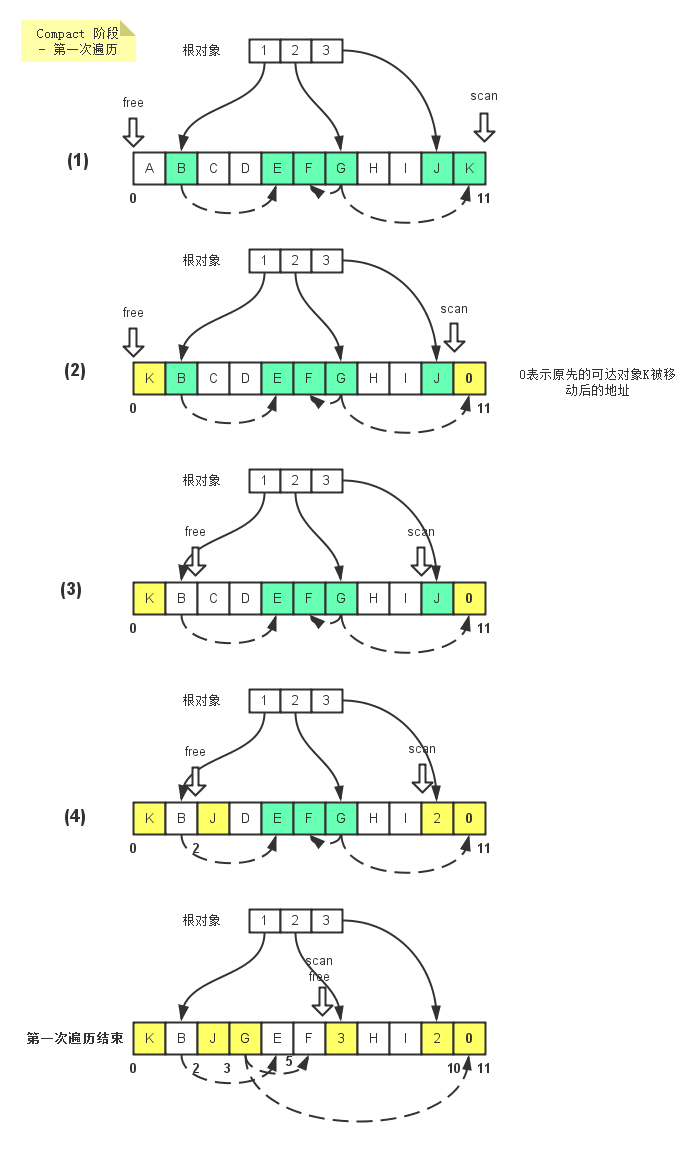
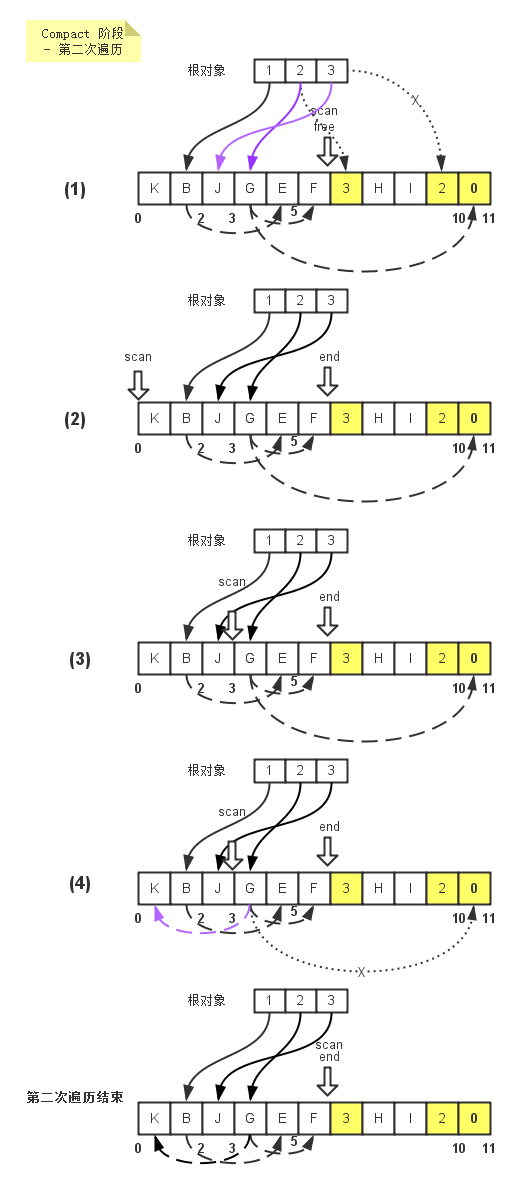
在Java里, 当一个对象o被创建时, 它被放在Heap里. 当GC运行的时候, 如果发现没有任何引用指向o, o就会被回收以腾出内存空间. 或者换句话说, 一个对象被回收, 必须满足两个条件: ==1)没有任何引用指向它 2)GC被运行==.
在现实情况写代码的时候, 我们往往通过把所有指向某个对象的==referece置空==来保证这个对象在下次GC运行的时候被回收 (可以用java -verbose:gc来观察gc的行为)1
2Object c = new Car();
c=null;
对于简单的情况, 手动置空是不需要程序员来做的, 因为在java中, 对于简单对象, 当调用它的方法执行完毕后, 指向它的引用会被从stack中popup, 所以他就能在下一次GC执行时被回收了.
但是也有例外,当使用==cache==的时候, 由于cache的对象正是程序运行需要的, 那么只要程序正在运行, cache中的引用就不会被GC给(或者说, cache中的reference拥有了和主程序一样的life cycle). 那么随着cache中的reference越来越多, GC无法回收的object也越来越多, 无法被自动回收. 当这些object需要被回收时, 回收这些object的任务只有交给程序编写者了. 然而这却违背了GC的本质(自动回收可以回收的objects).
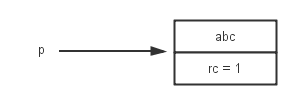
==所以就引入了weak reference==1
Object c = new Car(); //只要c还指向car object, car object就不会被回收
1 | WeakReference<Car> weakCar = new WeakReference(Car)(car); |
当要获得weak reference引用的object时, 首先需要判断它是否已经被回收: ==weakCar.get();==
例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class Car {
private double price;
private String colour;
public Car(double price, String colour){
this.price = price;
this.colour = colour;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getColour() {
return colour;
}
public void setColour(String colour) {
this.colour = colour;
}
public String toString(){
return colour +"car costs $"+price;
}
}
1 | import java.lang.ref.WeakReference; |
程序运行一段时间后, 程序打印出”==Object has been collected==.” 说明, weak reference指向的对象的被回收了.
WeakReference的一个特点==是它何时被回收是不可确定的, 因为这是由GC运行的不确定性所确定的==. 所以, 一般用weak reference引用的对象是有价值被cache, 而且很容易被重新被构建, 且很消耗内存的对象.
ReferenceQueue
在weak reference指向的对象被回收后, weak reference本身其实也就没有用了. java提供了一个ReferenceQueue来保存这些所指向的对象已经被回收的reference. 用法是在定义WeakReference的时候将一个ReferenceQueue的对象作为参数传入构造函数.
1 | Reference(T referent, ReferenceQueue<? super T> queue) { |